ナンテコッタ、アナコンダ!
22年秋のこと。Google Colaboratoryでtensorflowを動かそうとしたら、、、エラーで動かない。 調べてみるとTensorFlow 1.x系のサポートが正式に終了したとのこと。ナンテコッタ!
また画像データを学習させてモデルをラズパイに組み込んで動かすには、
- ラズパイでTensorFlow 2.x系を動かせるようにする
- Google Colaboratory以外でTensorFlow 1.x系を動かせるようにする
という2通りがあるが、これを機に自分のPC内に画像を入れたまま学習できるようになるのがいい思って後者を選び、AnacondaをWindows PCに入れてやってみることにした。
1.インストールの注意点
Anaconda公式サイトからインストーラをダウンロードしてインストールが終わった後、Anaconda Navigatorを立ち上げる。このあとTensorFlowの仮想環境を準備するが、TensorFlow 1.x系が動くようにするためにpythonは3.7.x を選ぶようにする。Anacondaのことを紹介した記事などは他にもあるが、このブログで言いたかったことはこの点だけである。
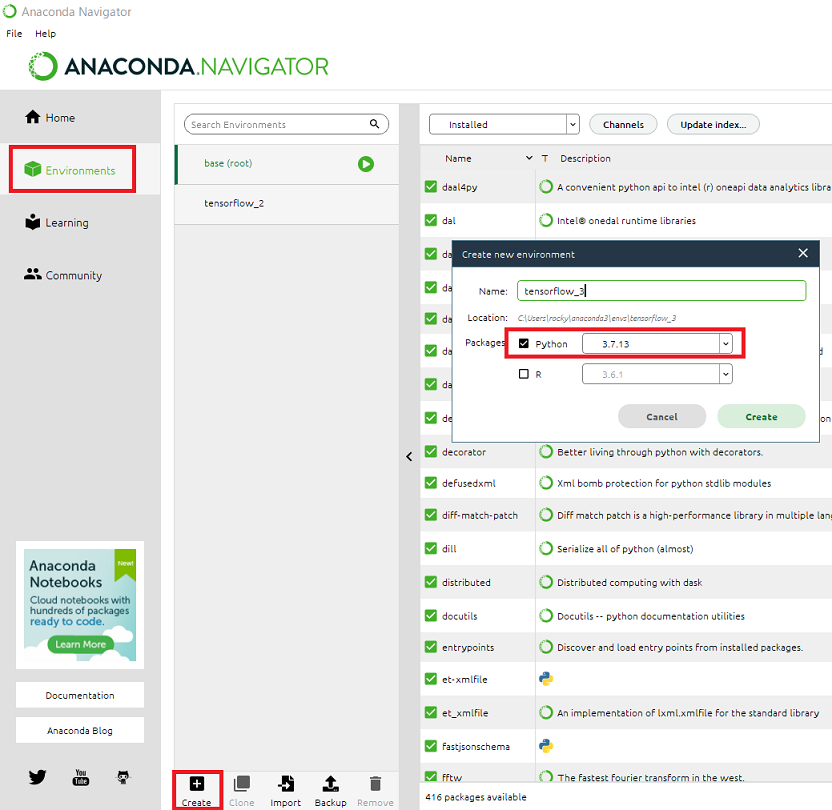
次にJupyter Notebookをインストールする。

tensorflowのインストールにあたってはTerminalを立ち上げ、

pipを最新化したあとでバージョンを指定してインストールする。
pip install --upgrade pip
pip install tensorflow==1.14.x.
Google Colaboratoryで使っていたソースコードはJupyter Notebookを立ち上げて移植し、動作を確認する。

これで環境は立ち上がった!Colaboratoryを使っていればJupytorの操作性はさすが違和感なし。本業がH/W屋さんである筆者にとって”仮想環境”といえばS/W屋さんの口から出てくる異世界のキーワードのように感じていたが、ついに足を踏み入れてしまった感覚である。これでラズパイ側は変更なしで続けられるようになったゾ。おしまい。
ラズパイ× tensorflowでプラレール自動運転(3) 学習したモデルでエッジコンピューティング
tensorflowで駅の写真を学習・推論させ、プラレールをラズパイで自動運転する第3回!学習させたモデルを使い、エッジで推論させながら駅を見つけたら停車させます。
1.学習および動作環境
撮った写真はGoogle ColaboratoryでKerasを利用したpythonプログラムを組んで学習させます。出力層は「駅があるとき」「駅がないとき」の2層だけの分類とし、中間層を2層や3層、Dropoutさせたりさせなかったりしましたが評価データに対する精度=0.89くらい、F1スコア=0.85くらいなのはおよそ変わらず。世の中にころがっているサンプルと大きく変わらないので、この記載は省略。
ただし、Google ColaboratoryはデフォルトでTensorflow 2.x系が走ります。ラズパイの推論プログラムをTensorflow 1.x系で作っていて学習モデル読み込み時にエラーが起こったため、Google Colaboratoryで学習させる時は
%tensorflow_version 1.x
を実行して「TensorFlow 1.x selected.」と表示されたあとに学習プログラムを走らせます(これがうまく反映されないときは「メニュー→ランタイム→ランタイムを再起動」をクリック)。こうして同じディレクトリ内に生成される学習モデル「.h5ファイル」と「.jsonファイル」をラズパイにコピーします。
バージョンの不一致はつまずくポイントですよね。今回動作したバージョン一覧はこちら。
| 対象 | バージョン |
|---|---|
| ラズパイ | Raspberry Pi 3 Model B+ |
| OS | Raspbian GNU/Linux 10 (buster) OS image Release date:2021-05-07 |
| Keras | 2.3.1 |
| Tensorflow | 1.14.0 |
| python | 3.7.3 |
2.自動運転、やってみよう!
写真を撮りながら推論し、90%以上の確率で駅のある画像と判定されたら減速→停車→再力行と動かすプログラムは以下。
import numpy as np import keras from keras.models import model_from_json from keras.datasets import mnist import random, glob, picamera, time, shutil from keras.preprocessing.image import load_img, img_to_array import RPi.GPIO as GPIO from PIL import Image GPIO.setmode(GPIO.BOARD) # Raspberry Pi用 MAX14870搭載 デュアルモータードライバのピンアサイン DIR_1 = 18 DIR_2 = 22 EN_N = 29 PWM1 = 32 PWM2 = 33 # 各ピンを出力ピンに設定 GPIO.setup(DIR_1, GPIO.OUT, initial=GPIO.LOW) # LOW:forward GPIO.setup(DIR_2, GPIO.OUT, initial=GPIO.LOW) GPIO.setup(EN_N, GPIO.OUT, initial=GPIO.LOW) # LOW active GPIO.setup(PWM1, GPIO.OUT, initial=GPIO.LOW) GPIO.setup(PWM2, GPIO.OUT, initial=GPIO.LOW) # PWM オブジェクトのインスタンスを作成 p1 = GPIO.PWM(PWM1, 4000) p2 = GPIO.PWM(PWM2, 4000) #---------------------------------------------------------------- #モデルを読み込む(プログラムと同じディレクトリに入れておく) model = model_from_json(open('model_station.json').read()) #重みを読み込む(プログラムと同じディレクトリに入れておく) model.load_weights('model_station.h5') #損失関数、オプティマイザを指定 model.compile(loss='categorical_crossentropy', optimizer='adam') print("mode loaded") #---------------------------------------------------------------- # PWM信号を出力 p1.start(0) p2.start(0) p1.ChangeDutyCycle(1) p2.ChangeDutyCycle(1) try: while 1: #---------------------------------------------------------------- with picamera.PiCamera() as camera: camera.resolution = (640, 480) camera.rotation = 180 # 撮影し、ファイルに保存 camera.capture("pic_1_org" + '.jpg') #---------------------------------------------------------------- # 写真の右下(駅が映り込む部分)をトリミングする im = Image.open('/home/pi/Desktop/pic_1_org.jpg') im_crop = im.crop((320, 240, 640, 480)) im_crop.save('/home/pi/Desktop/pic_1.jpg', quality=95) filename = "pic_1" + '.jpg' #---------------------------------------------------------------- data = load_img(filename, target_size=(32,32)) #推論用の画像32x32で読み込み data = img_to_array(data) #3次元PILから3次元ndarrayに data = data.astype('float32')/ 255.0 #データを0.0~1.0へ正規化 data = np.expand_dims(data, axis=0) #次元を合わせる #--------------------------------------------------------------------- #推論する classifi = model.predict(data) #predsのインデックスでソートする index_sort = np.argsort(classifi) #最大のインデックスを出す index = index_sort[0][-1] #どのラベルと分類されたかを表示する label_list = ["nostation", "station_OK"] print("予測 : " +str(label_list[index])) #分類した結果の確率を表示する probability = preds[0][index] * 100 print("確率 : " + str(probability) + " %") #--------------------------------------------------------------------- if index == 1 and probability >= 90: p1.ChangeDutyCycle(0.2) #駅を見つけたら1秒間は減速して走る p2.ChangeDutyCycle(0.2) time.sleep(1) p1.ChangeDutyCycle(0.0) #2秒停車する p2.ChangeDutyCycle(0.0) time.sleep(2) p1.ChangeDutyCycle(0.2) #再びゆっくり走りだす p2.ChangeDutyCycle(0.2) time.sleep(1) else: p1.ChangeDutyCycle(28) p2.ChangeDutyCycle(28) except KeyboardInterrupt: # PWM を停止 p1.stop() p2.stop()
駅を見つけて停まった!

駅を発見できず通り過ぎることはなかったが、まれに全然関係ないところで勝手に停まるのはなんだろう、何を駅と間違えているのだ、、、。いずれにせよ学習データ集め~クラウドで学習~エッジで推論してH/Wを制御という一連の流れを行った。今後は、
- 推論側の処理速度向上・最適化
- 他の駅や前方に他の車両があるときも学習
- 分類ではなく回帰としてPWMの速度制御
ができそうかな。おしまい。
ラズパイ× tensorflowでプラレール自動運転(2) 学習用の写真を撮りまくる
tensorflowで駅の写真を学習・推論させ、プラレールをラズパイで自動運転する第2回!学習用の写真を撮るプログラムを2種類、作成しました。
1.どんな写真を学習させたらいいか
カメラを取り付けた様子がこちら。

写真を撮ると、こんな感じ。

背景に写っている物を誤認識されたくないので、駅が映り込む右下1/4の部分のみトリミングして取り込むことにする(←精度向上のためコレが大事でした!)。
2.走りながら写真を撮るプログラム
import tkinter as tk import picamera, time, shutil import RPi.GPIO as GPIO from PIL import Image # 写真ファイル名の連番スタート値を設定 count_0 = 0 # 使用するピン番号を設定(MAX14870) GPIO.setmode(GPIO.BOARD) DIR_1 = 18 DIR_2 = 22 EN_N = 29 PWM1 = 32 PWM2 = 33 # 各ピンを出力ピンに設定 GPIO.setup(DIR_1, GPIO.OUT, initial=GPIO.LOW) # LOW:forward GPIO.setup(DIR_2, GPIO.OUT, initial=GPIO.LOW) GPIO.setup(EN_N, GPIO.OUT, initial=GPIO.LOW) # Low active GPIO.setup(PWM1, GPIO.OUT, initial=GPIO.LOW) GPIO.setup(PWM2, GPIO.OUT, initial=GPIO.LOW) p1 = GPIO.PWM(PWM1, 3000) p2 = GPIO.PWM(PWM2, 3000) p1.start(0) p2.start(0) p1.ChangeDutyCycle(6) p2.ChangeDutyCycle(6) try: while (1): with picamera.PiCamera() as camera: count_0 += 1 camera.resolution = (640, 480) camera.rotation = 180 # カメラが上下反対なので反転する #camera.start_preview() time.sleep(0.2) #camera.stop_preview() camera.capture("pic_" + str(count_0) + '.jpg') # 右下1/4部分のみトリミングする im = Image.open('/home/pi/Desktop/pic_' + str(count_0) + '.jpg') im_crop = im.crop((320, 240, 640, 480)) im_crop.save('/home/pi/Desktop/pic_' + str(count_0) + '.jpg', quality=95) filename = 'pic_' + str(count_0) + '.jpg' source = r'/home/pi/Desktop/'+filename destination = r'/home/pi/Desktop/case0/'+filename shutil.move(source, destination) except KeyboardInterrupt: # PWM を停止 p1.stop() p2.stop()
- PWMのDuty比は6という小さな値でゆっくり走らせる。
- 右下1/4をトリミングした後、デスクトップにある「case0」フォルダに移動させる。
- 写真を撮るごとに変数count_0がインクリメントされ、ファイル名の連番になる。
- 動作を止めるには「Ctrl + C」
というプログラムです。 また、駅が映り込んだ瞬間のデータを増やすべく止まって撮るバージョンがこちら。
import tkinter as tk import picamera, time, shutil from PIL import Image count_0 = 0 count_1 = 0 count_2 = 0 class Application(tk.Frame): def __init__(self, master=None): super().__init__(master) # ウィンドウの設定 self.master.title("gather picture") self.pack() self.create_widget() def create_widget(self): self.label1 = tk.Label(self,text="3 case") self.label1.pack() def button0_click(): # button0をクリックした時の処理 with picamera.PiCamera() as camera: global count_0 count_0 += 1 camera.resolution = (640, 480) camera.rotation = 180 camera.start_preview() time.sleep(1) camera.stop_preview() camera.capture("pic_0" + str(count_0) + '.jpg') im = Image.open('/home/pi/Desktop/pic_0' + str(count_0) + '.jpg') im_crop = im.crop((320, 240, 640, 480)) im_crop.save('/home/pi/Desktop/pic_0' + str(count_0) + '.jpg', quality=95) filename = 'pic_0' + str(count_0) + '.jpg' source = r'/home/pi/Desktop/'+filename destination = r'/home/pi/Desktop/case0/'+filename shutil.move(source, destination) def button1_click(): # button1をクリックした時の処理 with picamera.PiCamera() as camera: global count_1 count_1 += 1 camera.resolution = (640, 480) camera.rotation = 180 camera.start_preview() time.sleep(1) camera.stop_preview() camera.capture("pic_1" + str(count_1) + '.jpg') im = Image.open('/home/pi/Desktop/pic_1' + str(count_1) + '.jpg') im_crop = im.crop((320, 240, 640, 480)) im_crop.save('/home/pi/Desktop/pic_1' + str(count_1) + '.jpg', quality=95) filename = 'pic_1' + str(count_1) + '.jpg' source = r'/home/pi/Desktop/'+filename destination = r'/home/pi/Desktop/case1/'+filename shutil.move(source, destination) def button2_click(): # button2をクリックした時の処理 with picamera.PiCamera() as camera: global count_2 count_2 += 1 camera.resolution = (640, 480) camera.rotation = 180 camera.start_preview() time.sleep(1) camera.stop_preview() camera.capture("pic_2" + str(count_2) + '.jpg') im = Image.open('/home/pi/Desktop/pic_2' + str(count_2) + '.jpg') im_crop = im.crop((320, 240, 640, 480)) im_crop.save('/home/pi/Desktop/pic_2' + str(count_2) + '.jpg', quality=95) filename = 'pic_2' + str(count_2) + '.jpg' source = r'/home/pi/Desktop/'+filename destination = r'/home/pi/Desktop/case2/'+filename shutil.move(source, destination) self.button0 = tk.Button(self,text="case 0", command=button0_click, width=30, heigh=3) self.button0.pack() # button0ウィジェット配置 self.button1 = tk.Button(self,text="case 1", command=button1_click, width=30, heigh=3) self.button1.pack() # button1ウィジェット配置 self.button2 = tk.Button(self,text="case 2", command=button2_click, width=30, heigh=3) self.button2.pack() # button2ウィジェット配置 if __name__ == "__main__": root = tk.Tk() app = Application(master=root) app.mainloop()
- 3つのボタンを配置し、分類させたいケースに合わせて格納フォルダを分けられる。
- 撮った瞬間に1秒だけプレビューを表示する。
- 各フォルダに格納時、右下1/4をトリミングする。
- 写真を撮るごとに変数count_0がインクリメントされ、ファイル名の連番になる。
実行時の様子がこちら。

ケースを分けられるようにしたのは、前方に他の車両がいて減速させるケースなどの実装も見込んでのことですが、駅があるときの停車だけを考える今回は、駅があるとき・ないときをそれぞれ20~30ずつ集めました。

では学習させてラズパイで実行(推論)してみよー。
ラズパイ× tensorflowでプラレール自動運転(1) モータドライバを準備する
AIで自動運転!わーい、この響きを実行したかった。
tensorflowで駅の写真を学習・推論させ、プラレールをラズパイで自動運転するまでを3回に分けて書いていきます。 今回はH/W編、「Raspberry Pi用 MAX14870搭載 デュアルモータードライバ」を動かします。
1.接続の様子
以下のように6ピン余るようにGPIOピンに挿します。ラズパイは「Raspberry Pi 3 Model B+」です。

MAX14870は4.5V以上の電圧が必要なので、単三電池4本をモータ駆動用の電源とします。3本だと電池が新品の時しか動きませんでした。このMotor Driver Output端子とプラレールの電池ボックス端子を配線します。
1.サンプルプログラム
ライブラリも公開されていますが、接続確認のために2秒だけモータを回す簡単なプログラムを載せておきます。
import RPi.GPIO as GPIO import time GPIO.setmode(GPIO.BOARD) # 使用するピン番号を設定 DIR_1 = 18 DIR_2 = 22 EN_N = 29 PWM1 = 32 PWM2 = 33 # 各ピンを出力ピンに設定 GPIO.setup(DIR_1, GPIO.OUT, initial=GPIO.LOW) # LOW:forward GPIO.setup(DIR_2, GPIO.OUT, initial=GPIO.LOW) GPIO.setup(EN_N, GPIO.OUT, initial=GPIO.LOW) # Low active GPIO.setup(PWM1, GPIO.OUT, initial=GPIO.LOW) GPIO.setup(PWM2, GPIO.OUT, initial=GPIO.LOW) # PWM オブジェクトのインスタンスを作成、周波数:3000Hz p1 = GPIO.PWM(PWM1, 3000) p2 = GPIO.PWM(PWM2, 3000) # PWM信号を出力 p1.start(0) p2.start(0) p1.ChangeDutyCycle(50) p2.ChangeDutyCycle(50) # 2.0秒待つ time.sleep(2.0) # PWM を停止 p1.stop() p2.stop() GPIO.cleanup()
さあ次は学習用の写真をとりまくるぞー!
ラズパイのnode-redとESP32(Arduino)でMQTTするときにつまずいたこと3つ
ラズパイのnode-redでMQTTを用いて、ESP32(Arduino)からpublishされたセンサ値を取得したいときに気を付けることを3つ、備忘録としてメモ。
1.node-redのバージョンは最新に
beebotteを使ってMQTTのノードを設定するには
- サーバ:mqtt.beebotte.com:8883
- トピック:(例えば) test/ras_1
- SSL/TLSを接続を使用、にチェック
- セキュリティタブからユーザ名にtokenを入れる(token:token_xxxxxxxx)
とするだけで良いはずだが、これらを設定しても接続状態にならずブローカーへの接続に失敗していた。
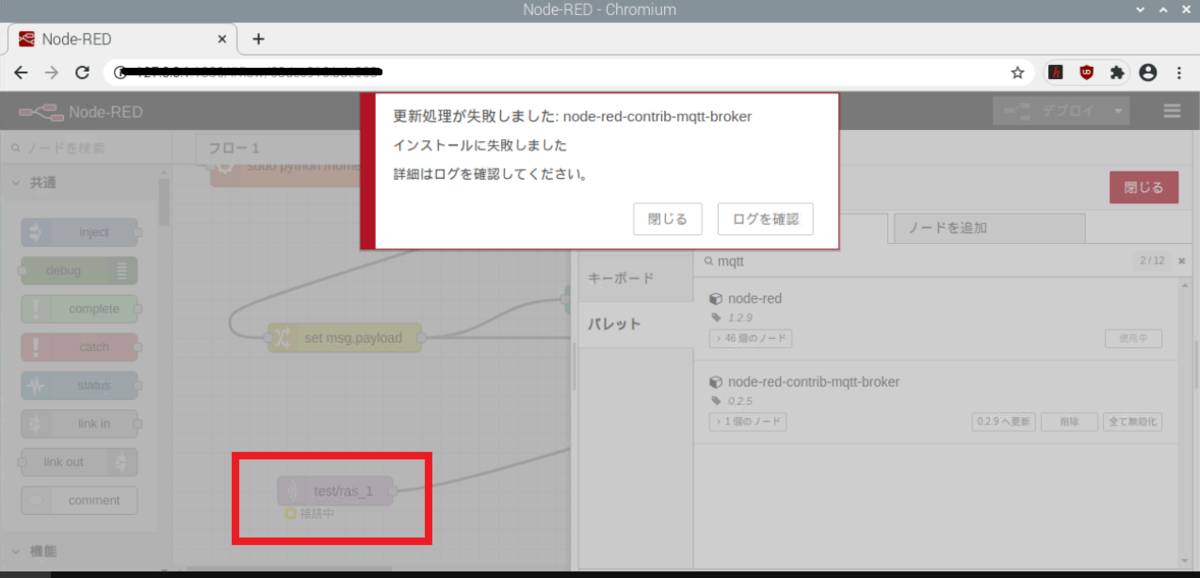
思えばラズパイのmicro SDカードを作成したのは1年以上前だった気がする、、、。npmの更新でエラーが出ているようで、npmを更新するためのコマンドをいろいろ試したが解決に至らず。けっきょく、
micro SDカードの作成からやり直した!
すると何事もなかったかのように接続に成功。ブローカーへの接続に失敗したら可能性の1つはバージョンを疑おう。
ちなみに、21年12月現在でラズパイ公式のイメージ書き込みツール「Raspberry Pi Imager」を使うとmicro SDカードの作成はとっても楽になったが、最初からnode-redは入っていなかったので
sudo apt install nodered
でインストールしよう。また、ダッシュボードのノードも入っていなかったのでパレットの管理から「node-red-dashboard」を検索してノードを追加しよう。
2..subscribeとpublishでtopicは変える
ESP32(Arduino)側の話。subscribeとpublishを両方実装していて同じtopicにしてしまうとArduino IDEのコンパイルでエラーが出るので、topicは分けよう。
3.センサ値をpublishするときの型変換
これもESP32(Arduino)側の話。以下はint型の"v"でセンサ値を取得したときに、それだけをpublishするソースコード。wifiやMQTTブローカーへは接続できているものとして、mainのloop内で型変換するにあたって必要な箇所のみ抜粋する。
const char* topic_2 = "test/ras_1"; void loop() { int v = get_data(); // センサ値取得の関数 String data = String(v, DEC); int length = data.length(); char msgBuffer[length]; data.toCharArray(msgBuffer,length+1); payload = msgBuffer; client.publish(topic_2, payload); Serial.print("MQTT published "); }
こうしてnode-redのダッシュボードでいうgauge(メーター)やchart(グラフ)で値を表示できるデータとして飛ばすことができる。
おしまい。
ミニ四駆アニメのワンシーンを爆速で体現する~Node-redで音声認識~
筆者のモノづくりの原点と言えば、小中学生時代のミニ四駆でした。 当時のアニメでは「行けーっ」と叫べばミニ四駆が走ったり飛んだりしたものです。これを大人になった今、やってみます。
音声認識をどうする??
ラピットプロトタイピングで(会話ではなく機器を指示するための分類器として)音声認識させたいとき
という方法もありますが、今回は”Red moblie”を使います。これにspeech to textノードが標準搭載されているので入力された音声を分類し、その結果をMQTTで機器に飛ばして制御します。
Red mobileでNode-redを準備する
Red mobileはAndroidで動作するNode-redのアプリです(有償ですが買い切りで使い続けられます)。 インストールして起動すると以下の画面になります。
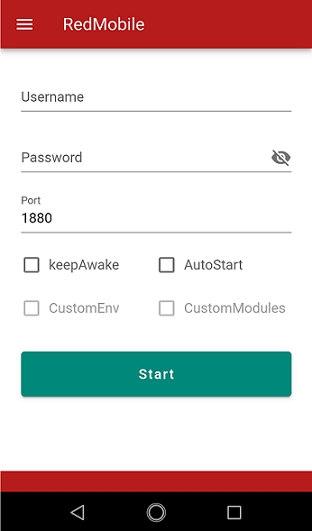
「Start」を押してしばらく待つと「Start」が「http:://~」というアドレスに変わるので、このアドレスをPCのブラウザからアクセスし、node-red編集画面を開きます。 ノードの中からspeech to textやダッシュボードで音声認識を起動するボタン、マイコンに指示するMQTT OUTなどを接続します。MQTTはbeebotteを使いました。

speech to textノードは以下を流すと起動できます。日本語対応、入力している言葉の候補を5つ生成させる設定を含んでいます。
//音声認識起動ノード msg.payload = { "language": "ja-JP", "matches": 5, "prompt": "please talk", "showPopup": true } return msg;
次にspeech to textノードが出力した文字列を連結し、
「行」が含まれていたら→{"data":"go"}
「止」が含まれていたら→{"data":"stop"}
に指示を分類してMQTTで送るメッセージを生成します。
//テキスト分類ノード var str_voice = msg.payload[0] + msg.payload[1] + msg.payload[2] + msg.payload[3] + msg.payload[4]; var result_go = str_voice.search( '行' ); var result_stop = str_voice.search( '止' ); if (result_go >= 0){ msg.payload = {"data":"go"}; return msg; }else if(result_stop >= 0){ msg.payload = {"data":"stop"}; return msg; }
var result_go = str_voice.search( '行' );
はstr_voiceに「行」が含まれていたら1以上の値、含まれていなかったら-1を返します。
ではやってみよう!
機器側はマイコンをESP32として、モータ制御に「Raspberry Pi用 MAX14870搭載 デュアルモータードライバ」を使いました。ESP32でMQTTメッセージをサブスクライブし、goならモータON、stopならモータOFFとします。ミニ四駆に組み込んで単独で走らせることまでは考えず、まずはつなげてモータ回しまでやってみます。
Node-redをデプロイし、スマホのRed mobileからダッシュボードを立ち上げます。

回った!何年かぶりに聞いたこのモータ音!

やってみた感想
一人でやっていたとは言え、「行けー、マグナム」と叫ぶのが思った以上に恥ずかしかった。大人になってしまったんだと思った。
おしまい。
光る紙で”ピカッ”とあのキャラが夜の足元を照らす
”ヒカルカミ(光る紙)”なるものをスイッチサイエンスで購入しました。

フレキシブル有機EL照明で、薄くて曲げられます。 端子に配線をはんだ付けして単三電池を3本つなげば、ほら光る。

最初は子供のおもちゃや絵本に仕込んで何かしようと思いましたが、思った以上に明るいので暗い廊下を照らすセンサーライトを自作することにしました。LEDセンサーライトではなく有機ELセンサーライトということになる。
構成要素
- マイコン :ESP-WROOM-32
- 照度センサ :TSL2561デジタル光センサ
- 人勧センサ :PIRモーションセンサ
- リレーユニット :セロワン リレー回路 拡張基板
- 光る紙用の電源 :単三電池3本
- マイコン用の電源:USBから供給
センサ類は珍しい情報ではないので詳細は割愛(ESP-WROOM-32の場合はArduino IDEでインポートできるTSL2561の標準ライブラリでは動作しないようなので注意)。ESP-WROOM-32のプログラムも照度が低いときにモーションセンサが検知していたらリレーをオンするだけのもの。
リレーユニットはマイコン系の電源と光る紙の電源を分けるために使いました。 これはラズパイセロ用の拡張基板でSRD-5VDC-SL-Cが載っておりAC 250V/10A, DC30V/10Aでオーバースペックですが手元にあったので活用。

問題は筐体である。 日常で実際に使って運用したいので見た目も重要だが、3Dプリンタで作るといった手間もかけたくない。
そこで探して出会ったのがコイツ。

メルカリで時計機能が壊れて出品されていたものを発見し即購入。時計をくりぬいて中に回路を埋め込むことにした。ちょうど時計があったところからフレキシブル有機ELや各センサーが出るように固定すれば完成。

実運用へ
暗い廊下に設置して、歩いてみると

光ってお出迎え! 光る紙が面として光るのが良い感じ。ふつーにLEDでもいいんだけどね。
おしまい。